The total size in bytes of all of the episode files
podcastData.totalDuration
The total duration in seconds of all of the episode files
A good place to include this data is on your About page. Here’s an example from the 500 Year Diary website’s about page template.
## Stats
There are {{ podcastData.numberOfEpisodes }} episodes of _500 Year Diary_,
weighing in at {{ podcastData.totalSize |readableSize:2}}
and lasting {{ podcastData.totalDuration |readableDuration:'long'|replace_last:', ',' and '}}.
As I was adding transcripts to my podcast websites, it occurred to me that there was another fun fact I could include on the about page: the total number of words spoken on the podcast.
WEBVTT
NOTE
This transcript was created on 2026-06-07 at 09:18:04
1
00:00:33.359 --> 00:00:37.679
Hello, dear listener, and welcome back to 500 year diary.
2
00:00:37.740 --> 00:00:46.140
The only Doctor Who podcast that's just thought of an excellent way you can get out of buying Christmas presents for your nieces and nephews this year.
3
00:00:46.200 --> 00:00:47.880
I'm Nathan.
4
00:00:47.939 --> 00:00:48.659
I'm Adam.
5
00:00:48.719 --> 00:00:50.219
And I'm Todd.
6
00:00:50.280 --> 00:00:53.820
It's Friday, the 10th of July, 2009.
Here’s a summary of the format:
Each VTT file consists of blocks of text separated by blank lines. The first of these blocks is a WEBVTT header, which tells the browser that this is a WebVTT file. After that, there are two kinds of block — note blocks and transcript blocks. Note blocks are just plain text, but transcript blocks consist of:
an optional line number
a required timestamp range consisting of two timestamps separated by an arrow (-->)
some lines containing the actual transcript content
Here’s a JavaScript function that takes VTT content, extracts the actual transcript content, counts all the words, and returns the result:
And so now we can use transcriptWordCount in our templates. Like this:
## Stats
There are {{ podcastData.numberOfEpisodes }} episodes of _500 Year Diary_,
weighing in at {{ podcastData.totalSize |readableSize:2}}
and lasting {{ podcastData.totalDuration |readableDuration:'long'|replace_last:', ',' and '}}.
The transcripts of all the episodes add up to {{ transcriptWordCount }} words.
And here’s the output:
And we’re done. Silly, but fun. As I’m writing this, Flight Through Entirety has a transcript word count of 3,033,973, and on Untitled Star Trek Project it’s 2,327,981. Am I wasting my life? Or am I hanging out with my friends chatting about my favourite TV shows? It’s impossible to tell.
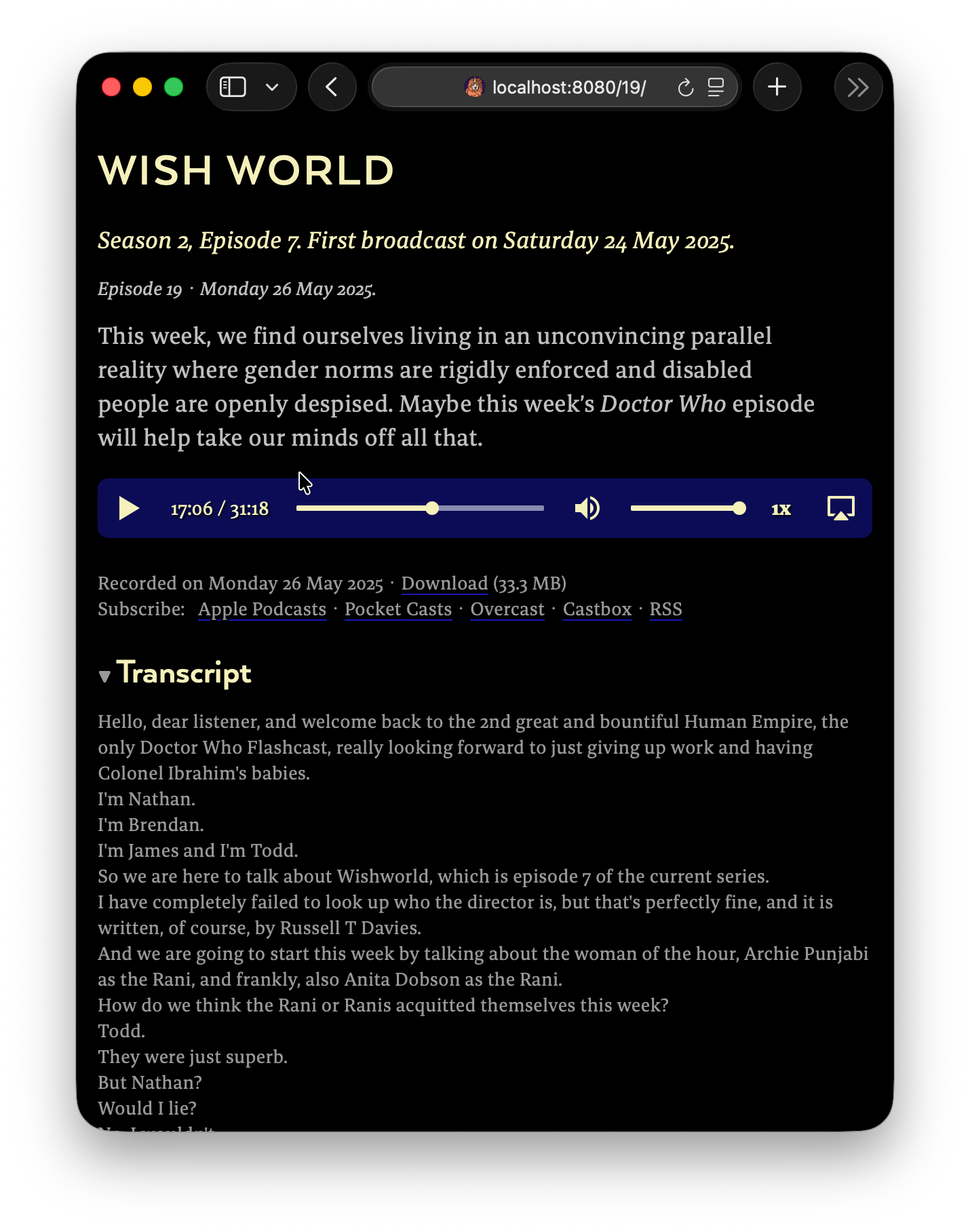
This transcript is interactive because it’s linked to the audio player on the page. If you click on the transcript, the audio starts playing from that point. And as the audio plays, the transcript highlights the phrase that you’re currently hearing, like the song lyrics in Spotify or Apple Music.
Let’s go through the implementation process together.
Transcribing the podcasts
First we have to get the podcast episodes transcribed.
What made me think I could even attempt this was the inclusion of the SpeechTranscriber class in macOS Tahoe, which I first heard about on Episode 684 of Accidental Tech Podcast. In that episode, Marco Arment explains how he uses SpeechTranscriber to transcribe all of the world’s podcasts for his Overcast podcast player.
Here’s a command-line tool that uses SpeechTranscriber: it’s called yap. We can use its transcribe command to transcribe a single podcast episode:
The --vtt option tells yap to output a VTT file, which is a format used on the web for subtitle files and other timed text tracks. The -m 65 option sets the phrase length to 65 characters. The -o option specifies the output file path.
It’s pretty fast. Even on my aging M1 MacBook Air, it takes about two minutes to transcribe a 60-minute episode.
WEBVTT
NOTE
This transcript was created on 2026-05-02 at 15:31:12
1
00:00:00.000 --> 00:00:03.180
Hello, dear listener, and welcome back to the 2nd great and
2
00:00:03.180 --> 00:00:06.660
bountiful Human Empire, the only Doctor Who Flashcast, really
3
00:00:06.660 --> 00:00:09.839
looking forward to just giving up work and having Colonel
4
00:00:09.839 --> 00:00:11.279
Ibrahim's babies.
You can see that this transcript includes the text of the episode divided up into short phrases, and that each of these phrases has a start and end timestamp. We’re going to call these phrases cues.
So now we can create a simple script that goes through the episode-files directory of our podcast project and transcribes each episode using yap, saving the transcript in the src/transcripts directory. It extracts the episode number from the episode filename and uses it to construct a filename for the transcript.
After running this script, we have a src/transcripts directory full of VTT files, one for each episode. Each VTT file is in the format 2gab-ep{num}-transcript.vtt, where {num} is the episode number.
Adding the transcript files to the site
Our next job is to add the transcript files to the site. Let’s define a permalink for each transcript file in a data directory file in the src/transcripts directory.
But defining permalink like that isn’t enough to get the transcript files to appear on the site. To get Eleventy to notice the files, in our Eleventy config file, we need to specify VTT as a custom template format and to tell Eleventy how to process the VTT files (by not changing them at all, as it happens).
eleventy.config.js
eleventyConfig.addTemplateFormats('vtt')
eleventyConfig.addExtension('vtt',{outputFileExtension:'vtt',compile:asyncfunction(content, _data){return()=> content // returns the content unchanged}})
Making the transcript file data available to the templates
Now we need to make the transcript files available to the episode post templates. It’s time for another directory data file. In this file, we’ll define a computed property called transcriptPath that returns the path to the transcript file, and another computed property called transcriptData that contains the parsed transcript content.
In the code example below, the parseTranscriptContent function divides the transcript content into cues separated by two consecutive newlines, and then parses each cue using the --> symbol that specifies the start and end timestamps and introduces the text of the cue.
src/episode-posts.11tydata.js
import fs from'node:fs'functiontoSeconds(timestamp){const[hh, mm, ss]= timestamp.split(':')return(parseInt(hh)*3600)+(parseInt(mm)*60)+parseFloat(ss)}functionparseTranscriptContent(content){return content
.trim().replace(/^WEBVTT.*\n/,'').split(/\n\n+/)// split into blocks separated by two consecutive newlines.filter(block=> block.includes('-->'))// filter out any blocks without a timestamp line.map(block=>{const lines = block.split('\n')const timestampLine = lines.find(l=> l.includes('-->'))const[start, end]= timestampLine.split(' --> ').map(toSeconds)const text = lines.slice(lines.indexOf(timestampLine)+1).join(' ')// join the remaining lines to get the textreturn{ start, end, text }}).filter(({ text })=> text)// remove any blocks without text}exportdefault{eleventyComputed:{transcriptPath(data){const episodeNumber = data.episode.episodeNumber
if(!episodeNumber)returnnullconst result =`./src/transcripts/2gab-ep${episodeNumber}-transcript.vtt`return fs.existsSync(result)? result :null},transcriptData(data){if(!data.transcriptPath)returnnullconst transcriptContent = fs.readFileSync(data.transcriptPath,'utf8')returnparseTranscriptContent(transcriptContent)}}}
So, now each episode post has a transcriptPath property which points to the transcript file, and a transcriptData property which contains the parsed transcript content. This content is in the form { start, end, text } where start and end are the timestamps in seconds, and text is the transcript text.
The transcript data is now available to the templates as {{ post.data.transcriptPath }} and {{ post.data.transcriptData }}. Let’s use them to add the transcript to the episode pages.
Displaying the transcripts
On every episode page, we have the episode title, some metadata, the blurb and an audio player (with some more metadata). These are defined in a partial called episode.liquid. Let’s add the transcript to that partial, just below the audio player and its caption.
The transcript now appears on the episode page in a <details> element at the bottom. The transcript comprises a series of <span class="cue"> elements. Each of these cues has a data-start and a data-end attribute: these are the timestamps for the start and end of each cue.
The problem with our transcript right now is that it’s just a massive block of text. yap and SpeechTranscriber don’t do any speaker identification, and the text isn’t divided into paragraphs. So let’s insert line breaks at the end of each sentence to make the transcript easier to read.
First we’ll define a custom filter called endsTheSentence that returns true if a given string ends with a sentence-ending punctuation mark.
And here’s the HTML for the start of the transcript:
<spanclass="cue"data-start="0"data-end="3.18">Hello, dear listener, and welcome back to the 2nd great and</span><spanclass="cue"data-start="3.18"data-end="6.66">bountiful Human Empire, the only Doctor Who Flashcast, really</span><spanclass="cue"data-start="6.66"data-end="9.839">looking forward to just giving up work and having Colonel</span><spanclass="cue"data-start="9.839"data-end="11.279">Ibrahim's babies.</span><br>
Making the transcripts clickable
So we have a visible, readable transcript, but it’s still not interactive. To make it interactive, we’re going to need to add some JavaScript: we’ll do that by adding a custom element to the partial. We’ll call it <episode-player>; its job will be to attach behaviour to the <audio> element and to the transcript.
Put the opening tag for the <episode-player> element before the <audio> element, and the closing tag after the <details> element that contains the transcript.
And here’s the first part of the code for the <episode-player> custom element. When this element is connected to the DOM, it attaches click event listeners to the transcript cues, so that clicking on a cue sets the current time of the audio element to the start time of the cue.
When the audio is playing, we can highlight the part of the transcript that corresponds to the words currently being spoken. To make this possible, we need to give the audio element access to the transcript. We do this by adding a <track> element as a child of the <audio> element, like this:
Now the HTMLTrackElement that corresponds to the <track> element on the page has a JavaScript property called track, which contains a TextTrack object. This object will emit cuechange events when the audio is playing; it also has an activeCues property that contains a list of the currently active cues.
Let’s add some code to the episode-player element so that it listens for these cuechange events, asks the TextTrack object for the current cue, and highlights the current cue on the page by adding an active class to the cue element.
And so we’re done. We now have an interactive transcript. You can click on it to play the corresponding part of the audio. And as the audio plays, the words being spoken are highlighted. You can see a transcript in action here.
By itself, the interactive transcript is a nice feature to have, but it can also be the basis of another, more useful feature. I’ve been working on using Pagefind to make my podcast websites searchable. But now that there are transcripts on my site, I can make the podcast episodes themselves searchable as well.
This blog post was written for Version 1 of Podcaster. The feature described here has been included in Version 2 — in fact it’s now the default. You can find out more about it here.
Each podcast episode in Podcaster is represented by a template with the tag podcastEpisode. On my podcast websites, I put all the podcast episode templates in a /src/posts directory, and I give each template the podcastEpisode tag by using a directory data file.
In my first post a few weeks ago, I showed you a simple way to create a home page for your podcast — by creating a template which loops through the podcastEpisode collection and renders some HTML containing the information for each episode.
Today, I’m going to show you an include file which presents more extensive detail about an episode. This include file can be used by itself on the episode’s dedicated page, but it can also be used as part of a list of episodes — like an index page or a tag page, for example.
An include file like this is sometimes called a partial.
Podcasts are an audio medium, of course, but your listeners’ podcast players describe each of your episodes using text — a title, a short description and a long description.
And so Podcaster lets you provide all three of those.
You can put whatever you want on your podcast site’s home page, but the most obvious and straightforward approach might be to present a list of episodes in reverse chronological order.